日本國立資訊學研究所(NII)的大規模語言模型研發中心(LLMC)開發出了兩款新一代國產LLM(大語言模型):約86億參數量的「LLM-jp-4 8B模型」(以下簡稱「4 8B模型」)以及約320億參數量的MoE模型「LLM-jp-4 32B-A3B模型」(以下簡稱「4 32B-A3B模型」),並於4月3日以開源許可方式對外公開。
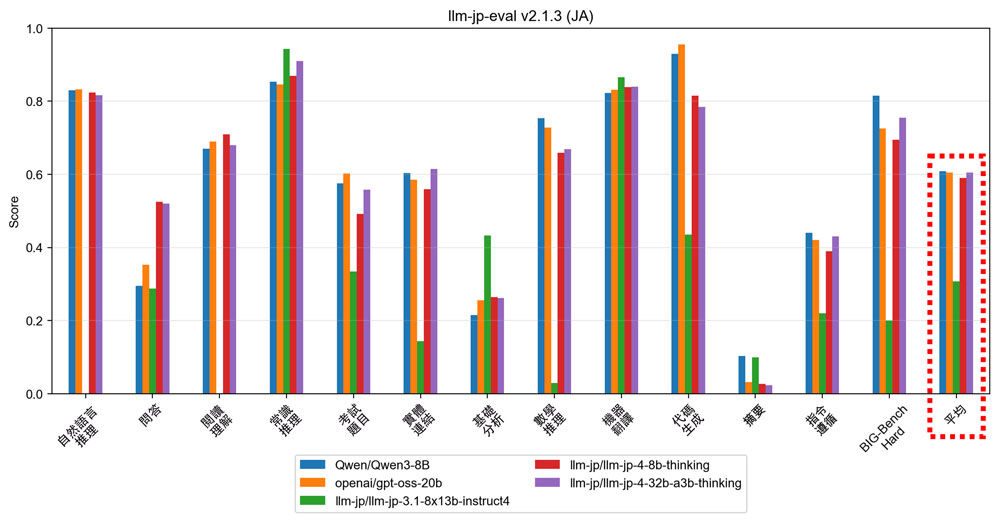
圖1 基於llm-jp-eval的代表性大語言模型分項評測(供圖:NII)
此次發佈的模型是在該中心主導的LLM研究開發社區「LLM-jp」的活動中,通過實施從零開始的完整訓練而開發出來的LLM,最大可處理約65,000個token(詞元)的輸入與輸出。
本次研發所用的算力資源為日本產業技術綜合研究所提供的AI橋接雲「ABCI3.0」。此外,「4 8B模型」採用Llama2架構,「4 32B-A3B模型」採用Qwen3MoE架構。
在訓練語料庫方面,研究團隊遵循開源AI定義(OSAID)的標準,在收集、篩選並構建了第三方亦可獲取的優質訓練語料庫的基礎上,構建了與該社區此前開發並發佈的「LLM-jp-3.1」系列相比規模擴大了約6倍的訓練語料。
在預訓練階段,研究團隊使用了由網際網路公開數據、政府及國會文件等構成的大規模預訓練語料庫。該語料庫總計約19.5萬億詞元,其中包含約7000億詞元的日語語料、約17.8萬億詞元的英語語料、約8500億詞元的其他語言(中文、韓文)語料,以及約2000億詞元的程序碼語料。
研究團隊通過實驗優化了各子語料庫在訓練中的使用權重,最終使用了合計約10.5萬億詞元的數據進行了預訓練。
在隨後的中間訓練階段,團隊使用了在預訓練語料庫基礎上添加了包含指令預訓練數據(Instruction Pre-training數據)在內的由大語言模型生成的合成數據,合計1.2萬億詞元的訓練語料庫。也就是說,前後兩個階段合計使用的訓練語料總量達到約12萬億詞元。
在微調階段,研究團隊使用了22種英語與日語的指令微調數據。這些訓練數據除具有開源許可證的數據外,還包含該社區開發的數據(計畫陸續公開)。
在對開發的模型性能評估方面,研究團隊採用了社區開發的評估框架「LLM-jp-judge」,並基於GPT-5.4進行了LLM-as-a-Judge評估。
結果顯示,在衡量日語理解能力的「日語MT-Bench」評測中,「4 8B模型」得分7.54,「4 32B-A3B模型」得分7.82,超越了「GPT-4o」的7.29、「gpt-oss-20b」的7.33以及「Qwen3-8B」的7.14。
在衡量英語理解能力的「MT-Bench」評測中,「4 8B模型」得分7.79,「4 32B-A3B模型」得分7.88,與「GPT-4o」的7.69、「gpt-oss-20b」的7.85以及「Qwen3-8B」的7.69相比,達到同等以上水平。
此外,研究人員依託基於該社區開發的現有日英雙語語言資源構建的涵蓋42項評測任務的跨向度綜合評測框架LLM-jp-eval v2.1.3進行了評估。
評估結果確認,此次發佈的兩款模型在日語性能方面均達到了與「gpt-oss-20b」和「Qwen3-8B」同等的水平。
該中心後續將利用此次開發的兩款模型,持續推進旨在確保LLM透明性與可信賴性的研究開發工作。此外,團隊正持續研發更大規模的模型,併計劃於本年度內陸續發佈。
原文:《科學新聞》
翻譯:JST客觀日本編輯部