今年春節前後,生成式AI大語言模型在全球科技界再次掀起波瀾。中國初創企業、杭州深度求索人工智慧基礎技術研究有限公司開發的智慧助手DeepSeek-V3在多項評測指標上與美國著名的OpenAI公司開發的GPT-3持平,甚至在某些方面超越了GPT-3。這一成就不僅展示了中國在AI領域的快速進步,也引發了全球對生成式AI大語言模型的廣泛關注。

作為一名AI從業者,筆者起初對這一消息持懷疑態度。畢竟,開發大語言模型(LLM)是一項極其燒錢、耗時的工程,每一項投資都以億美元為單位。怎麼可能用數百萬美元在短時間內就開發出如此高水平的產品呢?
果然,很快對DeepSeek的各種猜忌便見諸報導。歸納起來主要有兩點。其一,是懷疑DeepSeek繞過美國政府的禁令,事先囤積了英偉達的AI晶片;其二,是懷疑DeepSeek「非法」蒸餾了GPT-3等美國先進AI大語言模型。
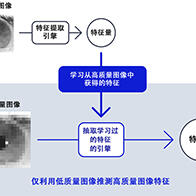
對於上述兩點猜忌,前者筆者無法求證,後者從技術角度看,使用了蒸餾技術應該屬實。蒸餾(Distillation)是機器學習,尤其是深度學習領域中使用的一種技術,旨在將大規模複雜模型(教師模型)的知識轉移到一個更小、更高效的模型(學生模型)中。該技術的目的是提高模型的推理速度並減少資源消耗。
蒸餾技術使學生模型能夠在保持與教師模型相當或接近的性能的同時,以更少的參數數量和計算資源運行。這對於在移動設備或嵌入式系統等資源有限的環境中實現AI應用尤其有效。
蒸餾技術允許學生模型在訓練過程中從教師模型(如GPT)中學習知識,並在訓練完成後獨立運行。這意味著,一旦學生模型(比如DeepSeek)通過蒸餾技術從教師模型中學到了知識,它就不再需要直接訪問教師模型來進行推理或預測。因此,即使未來GPT限制DeepSeek的訪問,只要蒸餾過程已經完成,DeepSeink的精度不會受到直接影響。
然而,蒸餾技術只能擷取某一時點的教師模型的知識,而教師模型本身還在不斷演化和改進。如果教師模型的新知識無法傳遞給學生模型,確實可能限制學生模型的進一步發展。換句話說,如果,DeepSeek僅僅是對GPT-3的蒸餾,那麼,今後如果GPT-3限制了對它的訪問或者禁止蒸餾,那麼DeepSeek的先進性將不會保持太久。
DeepSeek是否「非法」蒸餾了GPT,目前尚未有確切的報導。蒸餾的合法或合規是一件複雜的事,在得到賦權或許可的情況下的蒸餾是沒有問題的。而賦權的範圍以及應用條款,則因應複雜的商務合約,當事者之外不容置喙。這件事的真相到底怎樣,將來會有結論。
然而,DeepSeek出色的成績證明了,通過技術創新和資源優化,完全有可能在較短的時間內開發出高性能、低成本的AI模型。
DeepSeek的成功不僅激勵了中國的AI顯影器,也為全球的AI行業提供了新的思路。尤其是在日本,多家知名企業和研究機構也在積極開發適合本地需求的大語言模型,以應對日語處理的獨特性,並推動AI技術在商業和社會中的應用。
本文將重點介紹日本企業在開發大語言模型方面的最新進展,並通過具體實例展示這些企業在技術創新和應用場景上的獨特優勢。

1. 富士通:Takane(高嶺)—— 企業級大語言模型的代表
富士通作為日本領先的IT企業,近年來在生成式AI領域取得了顯著進展。2024年9月30日,富士通宣佈與加拿大AI公司Cohere Inc.合作,推出了企業級大語言模型「Takane」(高嶺)。該模型基於Cohere的LLM「Command R+」開發,並結合了富士通在日語處理方面的豐富經驗。Takane的核心特點如下:
強大的日語處理能力:Takane在日語理解能力上表現出色,尤其是在日本語言理解基準測試(JGLUE)中,其在自然語言推理(JNLI)和機器閱讀理解(JSQuAD)任務中表現優異,超越了其他競爭對手。此外,Takane還繼承了Command R+的多語言支持能力,能夠處理10種語言,適用於全球化企業的需求。
安全性與隱私保護:Takane設計為在私有環境中運行,確保企業數據的安全性。這對於金融、製造業和國家安全等需要處理敏感資訊的行業尤為重要。通過這種方式,富士通解決了企業在使用LLM時面臨的數據洩漏風險。
定製化與業務適配:富士通提供了針對企業特定需求的定製化服務,企業可以使用自己的數據進行微調,使Takane更好地適應其業務流程。此外,富士通還結合了Cohere的RAG(檢索增強生成)技術和自身的「知識圖譜擴展RAG技術」,進一步提升了模型的專業性和合規性。
Takane通過富士通的「DI PaaS」平台提供服務,與Fujitsu Uvance平台整合,幫助企業整合內外部數據,推動數據驅動的業務創新。這一平台不僅提升了企業的生產效率,還為跨部門協作提供了新的可能性。
2. NEC:cotomi系列——高速與高性能並重
NEC是日本另一家在AI領域具有深厚技術積累的企業。2024年4月,NEC宣佈推出新一代大語言模型「cotomi Pro」和「cotomi Light」,旨在滿足企業對高速響應和高性能的需求。cotomi系列的核心特點如下:
高速響應與高性能的平衡:cotomi Pro在性能上可與GPT-4和Claude 2等全球頂級模型媲美,但其應答速率是GPT-4的八分之一。而cotomi Light則在保持與GPT-3.5-Turbo相當性能的同時,進一步提升了處理速度,適用於需要快速響應的業務場景。
基於實際業務場景的優化:NEC通過分析其內部員工使用生成式AI服務的對話記錄,優化了cotomi系列在實際業務場景中的表現。例如,在未進行微調的情況下,cotomi在RAG(檢索增強生成)任務中的表現已超過GPT-3.5,而在微調後,其性能甚至超越了GPT-4。
低資源消耗與高擴展性:cotomi系列的設計注重資源效率,僅需1-2個GPU即可運行,降低了企業的硬體成本。這種高效的設計使得cotomi系列能夠廣泛應用於各類業務場景,從客戶服務到文件處理,均表現出色。
3. 國立情報學研究所(NII):llm-jp-3-172b-instruct3——開源大語言模型
日本的國立情報學研究所(NII)是日本在AI研究領域的領軍機構之一。2024年,NII宣佈公開其開發的大語言模型「llm-jp-3-172b-instruct3」,這是完全開源的LLM。llm-jp-3-172b-instruct3的核心特點如下:
完全開源與透明性: 該模型的所有訓練數據和碼均公開,確保了其透明性和可復現性。這種開源模式不僅促進了學術研究,還為企業和顯影器提供了寶貴的資源。
卓越的日語理解能力:在日語理解基準測試(llm-jp-eval)中,llm-jp-3-172b-instruct3的表現超越了GPT-3.5,展示了其在處理複雜日語任務上的優勢。
大規模訓練與高效計算:該模型基於2.1萬億個token進行訓練,參數量達到1720億,與GPT-3相當。NII利用日本的高性能計算資源(如AI擺渡雲(ABCI))完成了這一大規模訓練任務,展現了日本在AI基礎設施方面的強大實力。
4. 理化學研究所(RIKEN):Fugaku-LLM——富嶽超級計算機驅動
理化學研究所(RIKEN)與多家日本高校和企業合作,利用其超級計算機「富嶽」開發了日語能力卓越的大語言模型「Fugaku-LLM」。該模型於2024年5月10日公開,標誌著日本在高性能計算與AI結合領域的重要突破。Fugaku-LLM的核心特點如下:
基於超級計算機的高效訓練:Fugaku-LLM利用「富嶽」超級計算機的強大計算能力,完成了大規模的訓練任務。這種高效的計算資源使得模型能夠在短時間內處理海量數據,提升了訓練效率。
專注於日語優化的模型設計:該模型在日語處理任務中表現出色,尤其是在自然語言生成和理解方面,展現了其在日本文化和語言環境中的獨特優勢。
跨機構合作的典範:Fugaku-LLM的開發是日本學術界與產業界合作的典範。東京工業大學、東北大學、富士通等機構的共同參與,不僅加速了模型的開發進程,還為未來的AI研究奠定了堅實的基礎。
日本企業開發LLM的特點
從上述案例可以看出,日本企業在開發大語言模型時,具有以下幾大特點。
日語處理的深度優化:日本企業開發的LLM在日語處理能力上表現出色,能夠更好地適應日本的語言和文化環境。
安全性與隱私保護:日本企業特別注重數據安全和隱私保護,尤其是在金融、醫療和政府等敏感領域,提供了高度安全的AI解決方案。
高效計算與資源優化:通過利用超級計算機和高效的模型設計,日本企業在降低計算成本的同時,提升了模型的性能和應答速率。
跨領域合作與開源精神:日本的研究機構和企業之間的緊密合作,以及開源模型的推廣,為AI技術的普及和創新提供了強大的支持。
說一千道一萬,LLM不是用來看的,是拿來用的。只要能應用於各種場景,解決實際問題。就是好模型。日本企業在開發大語言模型方面展現了強大的技術實力和創新能力。無論是富士通的Takane、NEC的cotomi系列,還是國立情報學研究所的開源模型,乃至理化學研究所超算驅動的LLM,這些LLM不僅在技術測評的部分指標上達到了國際領先水平,還在實際應用中展現了獨特的優勢,能夠滿足特定領域的應用需求。積累了這些實戰經驗,隨著AI技術的不斷發展,日本企業有望在全球AI應用領域佔據更加重要的地位,推動AI技術在更多領域的應用與普及。
供稿 / 戴維
編輯 JST客觀日本編輯部