從事軟體開發的Human Techno System公司(東京中央區)與東北大學共同開發了一項技術,可以使有語言障礙的人合成其原來清晰的聲音。因ALS(肌萎縮性側索硬化症)等疾病或事故而導致語言發音不清的人可以通過該技術恢復健康時的聲音。該技術計劃2~3年内實現實用化。

完全按照客戶的語音語調讀出輸入的句子(供圖:Human Techno System)
當在電腦中輸入「早上好。今天的天氣也不錯」時,宛若再現了自己在講話時的聲音從電腦中發了出來。此次開發的就是為那些因疾病或事故等而出現語言障礙的人帶來這種生活場景的技術。
該技術讓人工智慧(AI)學習語言障礙者自身的聲音和健康人的聲音,然後以語言障礙者本人的語音語調合成清晰的聲音。由此,語言障礙者可以獲得「第二個聲音」。如果將該AI嵌入軟體中,就能以實現支持使用平板電腦等輸入或通過視線輸入本文的聲音合成系統。
「以往的聲音合成系統以如實再現所學習聲音的特徵為目的,因此有語言障礙的人很難使用」,在Human Techno System公司負責聲音合成軟體開發的渡邊聰說道。如果學習的聲音數據缺乏抑揚頓挫感,或者講話速度非常慢,那麼合成的聲音就容易不清晰。
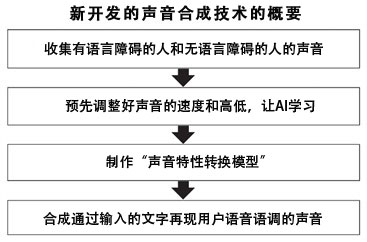
研究團隊此次開發了在保持清晰的抑揚頓挫感和節奏的同時,僅將語音語調轉換成客戶本人的聲音的技術,克服了這個挑戰。使用了名為「生成式對抗網路(GAN)」的AI法等。
該技術還能節省提供聲音數據的客戶的時間和精力。該公司過去開發的聲音合成軟體需要讓客戶朗讀和錄製近千種句型。而此次隻需約100~200種。如果因疾病的進展等而難以朗讀時,也可以使用過去錄製的聲音。
語言障礙者的聲音資料品質各不相同,比如聲音過於單調,或者因為用力而導致聲音劇烈起伏等。因此,研究團隊調整了讓AI學習的聲音的速度和高低,提高了聲音合成的質量。
未來打算與醫療機構和NPO法人等推進驗證實驗。「合成的聲音是否‘像本人’還存在很大的主觀性」(渡邊),因此將收集客戶及其家人的回饋。
該技術針對的症狀也將擴大到腦癱等疾病上。有語言障礙的兒童也將成為目標,需要改良聲音收錄法和軟體使用方法。該軟體的目標價格為幾十萬日元。
日文:高崎文、《日經產業新聞》,2022/5/2
中文:JST客觀日本編輯部