因原子能發電投資失敗而元氣大傷沉寂多日的東芝,2020年2月20日宣佈在世界上首次開發出了“可在終端上檢測關鍵字和識別說話者的人工智慧(AI)”。
這個技術屬於聲音認證的範疇。人類當從某處聽到別人的聲音時,即使看不到那個人的身影,也能明白“那個聲音是某某人的”。人的聲音,包含起因於聲帶和口腔等發聲器官的形狀的身體特徵。每個人說話方式都有習慣性特徵。從聲音中提取這種與個人相關的特徵,識別說話人的技術就是聲音認證。聲音認證,在技術上被稱為說話者識別(Speaker Recognition),或者說話者對照(Speaker verification),在很多情況下,是指將一對聲音進行比較來推斷它們是否是同一個人的技術。
日本廠家的新聞發布往往喜歡用“世界首發”這個詞。那麼,我們一起來看看東芝的這個“世界首發”含金量多少,“在終端上檢測關鍵字和識別說話者的AI”有什麼應用場景。
對於一般消費者而言,更熟悉話音辨識AI,譬如亞馬遜的Amazon Echo,谷歌的Google Home Hub,微軟的Microsoft Cortana,以及蘋果的Apple HomePod等智慧音箱。但是,這些智慧音箱的一個特點是線上輔助。因為AI話音辨識與翻譯需要龐大的計算,所以一般是利用智慧型手機這樣的高性能機器,或者將類似智慧音箱的設備通過網路在雲端計算。
而東芝的是在處理能力有限的終端上也能高速動作的語音關鍵字檢測技術,被稱為說話人識別人工智慧(AI)。按其官網解釋,如果將該技術搭載在家電上,即使家電不聯網,也可以通過3次說話就能將說話者登錄。說話者可以通過語音操作,變更家電的操作。
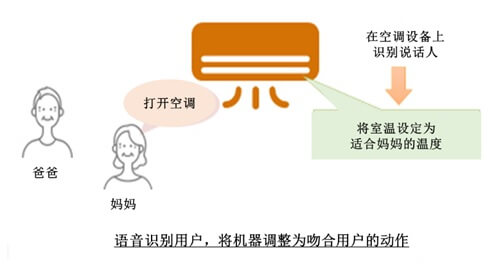
日常生活中,有許多不聯網的家電,要在這些終端上輕鬆使用話音辨識功能,就需要在其中嵌入中高速運行的AI。
東芝解釋說,這項技術有兩個特點。
其一,是靈活使用關鍵字檢測中的資訊。當輸入聲音時,在關鍵字檢測的神經網路中一邊吸收周圍噪音等的影響一邊進行聲音處理。利用神經網路的“中間輸出”,在說話者識別時也能夠抑制周邊的雜音的影響,大幅削減說話者識別的聲音處理的時間。從而在有限的功能上實現了高速動作。
其二,是利用神經網路的數據擴展方法。即用較少的數據進行學習的方法。即使說話者的發言數少也能夠對其學習,實現了註冊說話者時必要的發言數的削減。
東芝將該技術與一般的“i-vector”技術進行比較的結果是,前者的精度為89%,高於後者的71%。
i-vector是在1990年代GMM−UBM基礎之上經過改良的Joint Factor Analysis(JEA)模型。 使用從多數說話者的語音作成的音韻(各種元音、輔音)的標準模型,提取出標準模型和輸入語音的差分作為特徵量。因為單純地取得所有的差分就會變成涉及到10萬維的巨大的特徵量,所以i-vector的關鍵之處就是利用因數分析將其壓縮到400維左右的緊湊特徵量。
近年來,在圖形識別和話音辨識領域,應用深度學習來提高精度的嘗試很多。在聲音認證領域,從2014年左右開始,關於深水層學習的研究活躍起來,一個被稱為深水層說話者嵌入(Deep speaker embedding)的概念被業界注視。首先,訓練由特徵提取部和識別部構成的深水層神經網路,使其能夠從語音中正確推斷說話者。這樣形成的神經網路的特徵提取部,成為隻從語音中提取對說話者的識別有用的資訊的優秀的特徵提取器。
那麼,這種技術有什麼應用場景呢?因為每個人的語音都有獨特的生物特徵,所以,通過聲音認證技術就可以實現個性化服務,典型的商務應用場景如下。
電子化企業: 近年來,小額的信用卡付款大多采用無簽收方式。因為省略繁瑣的手續,減少購買行為的障礙,會給賣方和買方都帶來好處。可以說在當今的流通業界,除了安全、安心之外,還需要便利性。語音是人們在日常交流中使用的簡單的媒介,使用語音的生物檢定為客戶提供了簡便、輕鬆的本人確認手段。聲音認證是適用於電子化企業和電話術/網上銀行等商務交易中的本人確認的認證手段。
呼叫中心業務: 隨著企業客戶意向的提高,提高呼叫中心服務品質成為各個行業的需求。其中,比較迫切的課題是,簡化頻繁打電話術的重要顧客的本人確認手續,儘早確定投訴多的顧客等等。聲音認證是在看不見對方的電話術中使用的唯一的生物認證,可以通過自然的對話來識別客戶,因此對呼叫中心的業務支援非常有效。
犯罪搜查: 近年來,為了打擊以電話術詐騙,採取了各種各樣的對策。但是,這種犯罪卻巧妙化、組織化,絲毫沒有減弱。聲音認證,作為追蹤犯罪分子的腳印,支援搜查的分析工具受到重視。另外,電話術和社交網路服務(SNS)等作為監測犯罪組織動向的手段也是很重要的途徑。以聲音為線索的分析,比近年來在街頭迅速普及的監測攝像頭更能發現看不見的線索,以期為抑制犯罪做出貢獻。
供稿 戴維
編輯修改 JST客觀日本編輯部