計算能力掌握著AI競爭的未來。科學家們正在研究如何讓超級計算機學習海量數據開發人工智慧(AI),以實現作為新藥開發、材料開發和自動駕駛汽車等的劃時代技術。日本理化學研究所(以下簡稱「理研」)計劃利用全球最強的超級計算機「富嶽」的全部計算能力實現技術創新,類似的動向在歐美也日益明顯。

理化學研究所的超級計算機「富嶽」(圖片由理研提供)
理研預定2022年度利用富嶽的全部計算能力開發全球最大的AI系統。富嶽擁有16萬個CPU(中央處理單元),用於AI的話,每秒可進行約2Exa(1Exa為100京)次的計算。理研計劃利用全部的CPU,在新藥開發、材料開發和自動駕駛等各領域實現劃時代的AI系統。
AI開發一般先將不同目的(比如新藥開發或自動駕駛等)的數據大量輸入計算機讓超級計算機學習。但有時即使增加數據量,性能也無法提高,或者依然會做出錯誤的判斷。近年來針對學習方法的研究取得了進展,機器翻譯等領域已經可以通過增加數據量和計算量來提高性能。
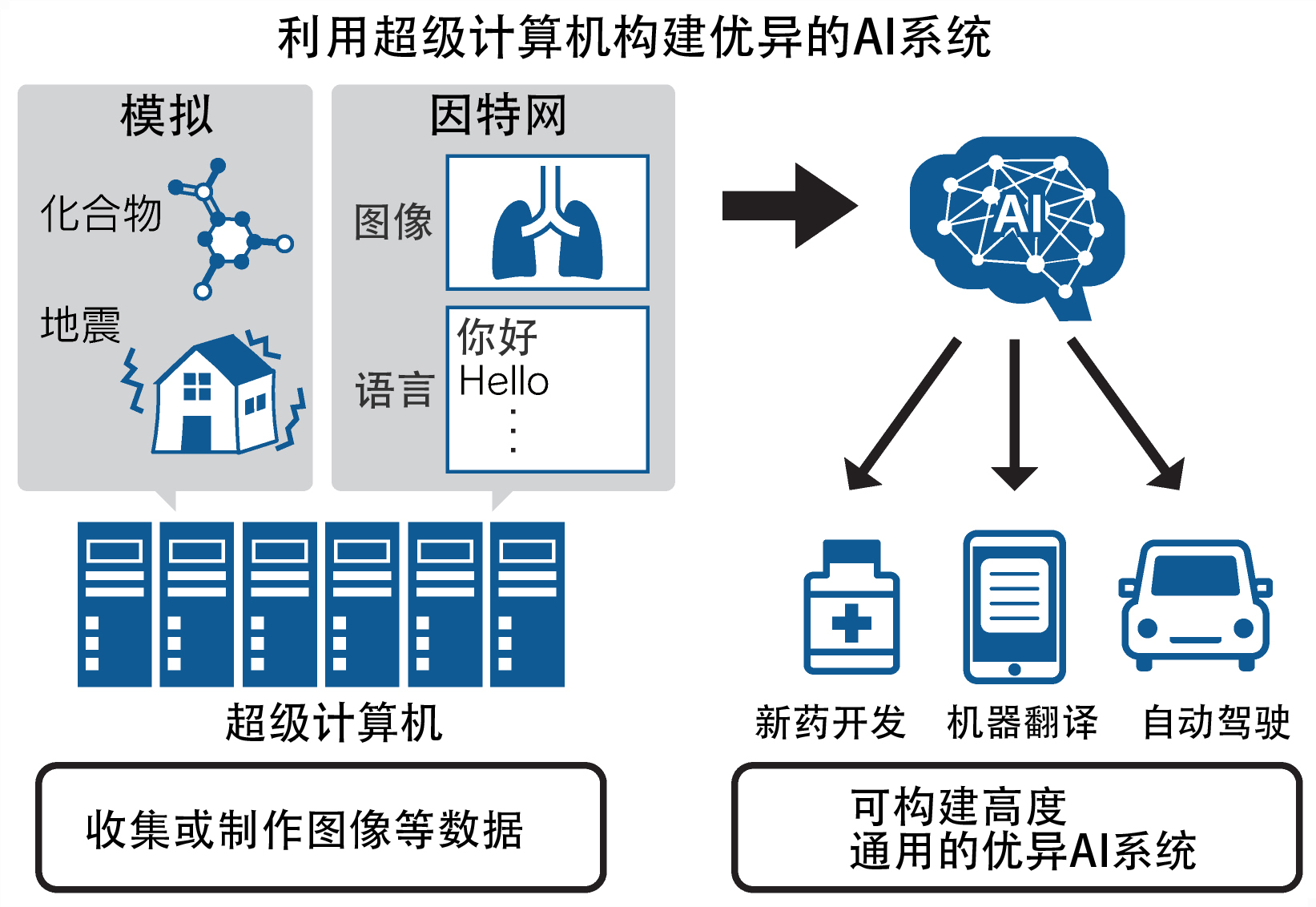
目前,研究的重點集中在超級計算機的計算能力、需要學習的數據量和影響計算結果的「參數」數量上。比如醫院的診斷用AI,其數據就包括性別、年齡和病史等項目。
之所以使用超級計算機,是因為需要學習大量數據。以汽車自動駕駛為例,據說一輛汽車行駛一年通過攝像頭和光感測器能收集到約2PB(1P為1000萬億)的數據。
理研計算科學研究中心主任松岡聰表示:「新藥開發、自動駕駛和機器翻譯等領域普遍要處理PB級以上的數據。要想利用如此大量的數據構建AI,必須有優異的超級計算機。」
理研的目標是開發劃時代的AI系統。美國微軟公司投資的研究企業Open AI於2020年6月公開的AI「GPT-3」能寫出接近人類水平的自然流暢的文章,並由此掀起了創新熱潮。GPT-3利用能處理1750億個參數的大規模計算模型提高了性能。
富嶽目前的計算能力位居世界第一,它可以在5120TB(1T為1萬億)的數據上運行訓練過的AI,這比GPT-3用於訓練的數據多出約114倍。預計參數的數量也在同等水平以上。
松岡介紹說:「可以大量生成圖像和化合物的結構數據,讓AI高速記憶。只有擁有利用超級計算機構建的AI,才能進行劃時代的新藥研究等。」目前的主流方法是,讓AI自己生成不足的數據並有效地進行學習。
理研還將利用富嶽詳細分析與疾病有關的體內蛋白質的結構,探索藥物的候選物質。目標是利用計算機斷層掃描裝置(CT)等的醫療圖像實現癌症的早期診斷。此外,還將大力開發預計將在2030年代實現的「L5」級別的汽車全自動駕駛AI系統。
利用超級計算機構建AI的主要舉措 |
|
研究主體 |
内容 |
理化學研究所(日本) |
利用“富嶽”試製全球最大的AI。為在超早期發現癌症和實現全自動駕駛開闢道路。 |
微軟(美國) |
與Open AI公司共同構建AI專用超級計算機。 |
英偉達(美國) |
擁有排名躋身全球前十的超級計算機,用於構建AI。 |
CINECA(意大利) |
正在構建全球最快的AI超級計算機“Leonardo”。 |
百度(中國) |
正在研究語音辨識和圖形識別及自動駕駛等 |
利用超級計算機開發AI的研究是美國谷歌和斯坦福大學於2011年開始推進的。目前中美處於領先地位,相關企業也引人矚目。「美國英偉達和微軟擁有位列全球前十的超級計算機。中國百度也在開發之中」(松岡)。
歐洲方面,意大利約100所大學和公共機構組成的研究者組織「CINECA」正在構建全球最快的AI用超級計算機「Leonardo」,擁有每秒10Exa次的計算能力,預定2022年投入使用。CINECA的負責人Sanzio Bassini表示:「將用來研究利用現有藥物治療新冠病毒感染症以及預測暴雨和地震等」。
AI備受期待。美國Alphabet公司旗下的英國DeepMind公司2020年11月開發出一款AI,解決了已存在半個世紀的生物學難題。該AI在短時間内預測出了有助於進行新藥開發的蛋白質的空間結構。
預計今後各國及各企業的競爭還會繼續。據Open AI公司估算,構建AI所需的計算能力約3個半月就會翻一番。日本產業技術綜合研究所(以下簡稱「產綜研」)人工智慧雲研究團隊的組長小川宏高表示:「利用超級計算機開發AI的競爭今後也會越來越激烈。」
要想取勝,需要向超級計算機投資並培養人才。產綜研等正通過舉辦講習會的方式致力於人才培養。小川組長表示,「日本國内企業很少有向超級計算機投資的」。如果錯過了構建大規模AI的浪潮,日本的產業競爭力可能會被進一步削弱。
日文:草鹽拓郎、《日本經濟新聞》,2021年4月5日
中文:JST客觀日本編輯部