日本國立研究開發法人產業技術綜合研究所(以下簡稱「產綜研」)全球首次開發出了利用由數學公式自動生成的大規模圖像數據集來構建AI圖形識別模型(預學習模型)的方法。這是通過NEDO(新能源產業技術綜合開發機構)「與人類共同發展的新一代人工智慧技術開發項目」獲得的結果。產綜研在6月19日至24日於美國新奧爾良舉辦的國際會議IEEE/CVF International Conference on Computer Vision and Pattern Recognition(CVPR)2022上介紹了開發的具體內容。
這種方法不僅實現了與目前使用真實圖像和經過人工判斷的教師標籤(為變成可以學習的形式,為圖像附加的標籤資訊)相同或更高的圖形識別精度,還解決了對AI識別圖像數據進行商業使用時存在的課題,比如收集大量供AI學習使用的真實圖像數據、確保圖像數據的隱私,以及削減添加教師標籤的成本等。該方法今後還有望應用於自動駕駛、醫療和物流等不同環境的AI構建。

圖1:無需基於真實圖像和人類判斷的教師標籤,而是通過由數學公式生成的教師標籤學習的圖像理解型AI概念圖(供圖:產綜研)
目前各個領域都在陸續引進AI,但製造和醫療現場等領域存在無法收集AI學習所需的大量數據的情況,以及為此需要付出高成本的情況,這成為引進AI技術的障礙。
因此,作為克服這一障礙的手段之一,利用AI通過大量各種真實圖像數據預先學習的圖形識別模型(預學習模型)的方法取得了進展。然而,學習圖像在數據透明性方面存在一些問題,比如侵犯隱私,或者不當添加的教師標籤輸出不公平的識別結果等,這成為了商業用途所面臨的課題。
因此,開發能在解決隱私侵犯和不公平的識別結果等圖像數據相關問題的同時,實現與原來相同或更高的識別精度的預學習模型,成為AI領域亟需解決的課題。
產綜研此次開發的方法在預先學習中完全不使用真實圖像,通過用數學公式(生成圖像模式和教師標籤的生成規則)自動生成圖像模式和教師標籤,可以削減添加標籤的成本,無需擔心真實圖像的數據數量、倫理問題和權利關係,能放心構建AI圖形識別模型(預學習模型)。

圖2:生成預學習模型使用的圖像示例。
圖上部是以前使用的標準真實圖像,中間和下部是此次提出的利用數學公式(碎形幾何/輪廓形狀)生成的圖像。(供圖:產綜研)
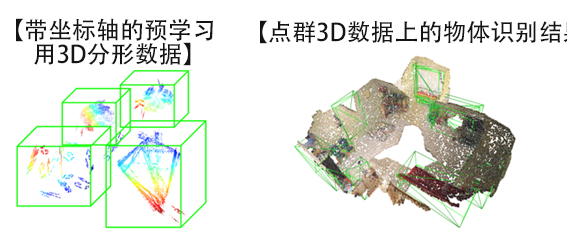
圖3:用於3D空間物體檢測的擴展數據集(供圖:產綜研)
另外,產綜研利用通過新方法構建的預學習模型識別了用於圖形識別性能測試的ImageNet的圖像數據集,確認比學習基於真實圖像和人工判斷的教師標籤的現行方法精度更高,達到了實用水平。

圖4:未來展望(供圖:產綜研)
該數據集及預學習模型已從6月13日開始在官網首頁(Formula-driven Supervised Learning)公開。
通過公開利用新方法構建的預學習模型,使用者可以從具有一定精度的圖像理解AI開始各自的開發。
原文:《科學新聞》
翻譯編輯:JST客觀日本編輯部
【論文資訊】
會議:IEEE/CVF International Conference on Computer Vision and Pattern Recognition(CVPR)2022
論文1:Replacing Labeled Real-image Datasets with Auto-generated Contours
論文2:Point Cloud Pre-training with Natural 3D Structures