美國開放人工智慧研究中心(OpenAI)研發的語言處理人工智慧(AI)網路聊天系統程序「ChatGPT」的發展令人矚目。在可以預想的未來社會中,人類將與能夠流利地使用多種語言進行高水平會話的 AI共存,那麼人類學習外語的意義又在哪裏呢?就此問題我們採訪了在日本資訊通信研究機構(NICT)長期研究機器翻譯的研究員隅田英一郎。

NICT隅田英一郎研究員
——迄今為止,機器翻譯是如何提高精準度的?
「機器翻譯歷史悠久,一般認為始於第二次世界大戰末期。在最初的約40年間,人們嘗試了根據文法等規則來處理翻譯,但效果並不理想。(僅憑規則)來處理語言存在侷限性。」
「2014年左右隨著深度學習技術(Deep Learning)的出現,翻譯準確度得到了飛躍性提升。以英語和日語為例,兩者文法和詞彙的差異很大,被公認為是‘距離最遠’的語言,可以說是最難翻譯的組合,如果以(滿分990分的)英語能力測試(TOEIC、國際交流用英語測試)來打個比方的話,現在的日英自動翻譯已經達到了900分的水平。」
——以後就沒有必要學習外語了嗎?
「學習語言可以瞭解文化,放眼世界的教育意義是不會改變的。然而,有分析顯示,英語母語者學習日語需要花費2200小時,與法語的600小時相比,需要付出巨大的時間和精力。因此,沒有理由不借助機器翻譯作為學習工具。事實上,機器翻譯在商業和學問上都很有效,即使是專業的譯者也在尋求共存之術。」
「掌握機器翻譯的使用訣竅非常重要。日語中省略主語或賓語,句子會顯得更自然,但英語中如果不把這些成分表述清楚的話,句子便不成立。所以怎樣才能讓機器翻譯出正確的英語,這就需要掌握不同語言的特點。」
——ChatGPT這樣的大規模語言模型會改變翻譯行業嗎?
「由於ChatGPT對行文的理解能力很強,大家都對它寄以厚望,但ChatGPT能否提升機器翻譯的性能尚不能一概而論。已經實現了高精度大的機器翻譯的基本模式應該不會因ChatGPT發生劇烈變化。」
「NICT針對專利和製藥等專業領域開發了多個機器翻譯系統,通過細分行業領域來提高翻譯的準確性。我們收集政府機構和企業擁有的數據構築了‘翻譯庫’,匯集了經過人工審覈過的高質量數據。我們已經掌握了即便數據量較少也能高精度翻譯的訣竅,今後會在不斷試錯中推進研究取得進展。」
「大規模語言模型值得期待的一個事情是,即使對於那些積累數據較少的少數語言,也有可能達到一定程度的翻譯精度。這對於印度那樣重視語言多樣性的國家來說,將是一項非常有益的技術。」
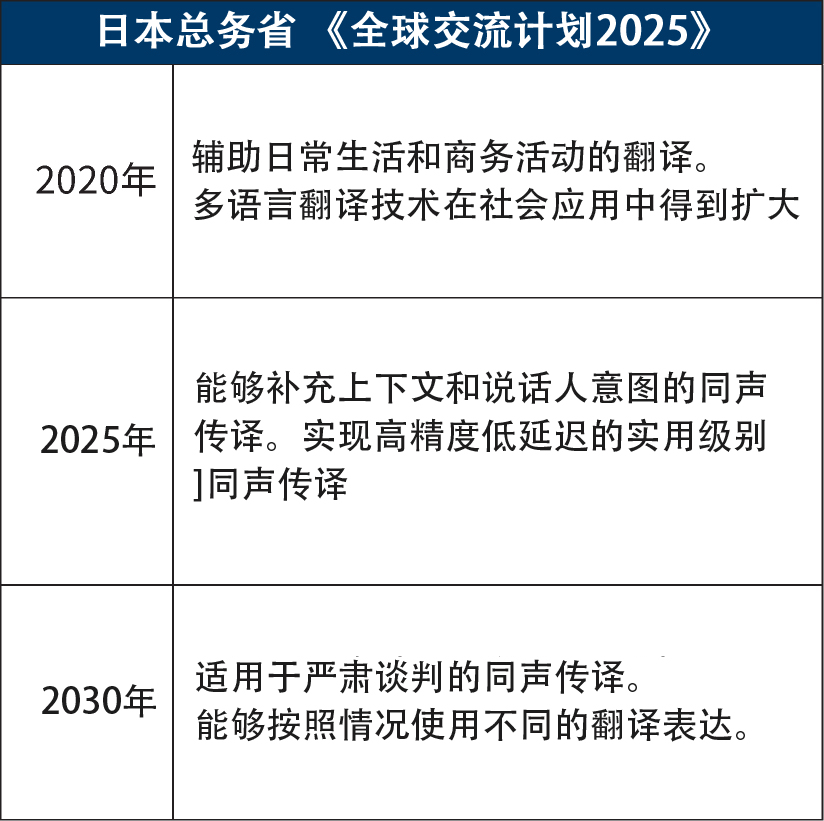
日本總務省正在推進一項名為《全球交流計劃2025》的計劃,該計劃旨在實現能夠補充上下文和說話人意圖等的同聲傳譯。該計劃由NICT牽頭研發,計劃在2025年國際博覽會(大阪·關西萬博會)上實際應用於多語種同聲傳譯系統。
機器翻譯長期以來一直被認為「無法實用」,但在大量基礎研究的基礎上,加上深度學習技術的出現,局面發生了明顯改變。ChatGPT以其高超的對話和總結能力震驚了世界,它蘊含著從根本上改變人類交流方式的可能性。
儘管社會上關於AI將奪走人類工作的威脅論盛行,但隅田認為:「和日本象棋一樣,未來主流還是人工翻譯與AI的共存。」重要的是如何利用AI,去拓寬人類的能力。學習語言,探索新的世界和文化,是人類相互理解的第一步,這點無論過去還是將來都不會改變。
日文:水口二季、《日經產業新聞》、2023/4/3
中文:JST客觀日本編輯部