五十嵐 健夫 Igarashi Takeo
東京大學 研究生院資訊理工學系研究科 教授
2017年度~2022年度 CREST研究代表
當下正處於人工智慧(AI)和機器學習變革期,更易於使用的計算機系統的用戶介面(UI)技術和人機交互技術變得越發重要。東京大學研究生院資訊理工學系研究科五十嵐健夫教授接連開發出了將我們腦中的所想快速轉換為三維圖形技術(3DCG)、動畫生成技術、虛擬試衣技術以及防止AI進行誤判的「共現偏差」消除技術等AI技術的前緣應用,不斷追求實現人與機器之間更良好的關係。
客戶客製化3D模型生成
震驚全球的圖像創作者的交互技術
在屏幕上轉列的二維(2D)角色草圖能夠瞬間轉化為具有毛絨玩具逼真感覺的三維(3D)計算機圖形技術(CG)。這個系統的設計思路是東京大學研究生院資訊理工學系研究科的五十嵐健夫教授早在24年前就已經考慮了。1996年,當時還是東京大學博士生的五十嵐教授作為實習生訪問了美國布朗大學,當看到用多面體表示的3D模型建立手繪風格插圖的CG技術時,受到了極大的震撼。
「我原本就對3DCG很感興趣,一直在尋找一種將筆繪草圖能夠變得立體化的機制。當看到布朗大學的CG技術時,就激發了‘反其道而行之’的靈感」。當時,正是全球首部長篇3DCG動畫電影《玩具總動員》上映的第二年,也是全世界開始關注3DCG的時期。五十嵐教授將研究重點放在了基於二維草圖的3D模型的研究課題上,並於1999年在全球計算機圖形學盛會SIGGRAPH 99上發表了名為「Teddy」的基於2D草圖的3D建模技術的論文(圖1)。

圖1 Teddy的3DCG創作示意圖
根據畫面上轉列的2D草圖(左)來自動生成3D模型(右)。可以從任何角度轉列並即時編輯三維模型(著色使用了其他軟體)。
該技術一經發布就引起了轟動,震驚了全世界的研究人員和圖像創作者。在人們的普遍認知中,傳統的3DCG是由具有專業技能的工程師和創作者來創作的,普通用戶只能使用其創作結果。而Teddy將3DCG創作從專業人士交到了非專業人士的手中,創造了一個無需任何特殊培訓即可輕鬆建立和編輯3D模型的世界。
基於這一成果,五十嵐教授還成功開發出了「空間關鍵幀法」。這是一種隻需在屏幕上進行少量操作,就能使由草繪創意實現的3D角色具有流暢動作從而生成即時動畫的技術。這些技術帶來了連五十嵐教授本人都始料未及的巨大社會反響,其中部分技術已應用於建立3D模型的標準PC軟體「Shade」中並實現了商業化。Microsoft的「Paint 3D」和Adobe的圖像軟體等類似產品也隨之面世。
根據不同體型和姿勢的具象化
費時3年開發出「虛擬試衣法」
然而,五十嵐教授的研究目的並不僅限於提高三維模型和CG圖形製作效率。「為了讓計算機系統更容易讓人使用,還需要考慮人和系統應該如何交互。客戶應該如何將頭腦中所想的圖像傳達給系統,系統輸出的結果又應該如何讓客戶來使用?這是一直以來都在研究的課題」。
研究生期間,五十嵐教授曾在美國施樂帕洛阿爾託研究中心、微軟研究院、卡内基梅隆大學有過實習經歷,也曾在日本電報電話術公司(NTT)、理光等公司實習。然而民營企業需要為開發的技術申請專利,商品化也多侷限於自己的公司。相比之下,大學的研究自由度更高,更有可能擴大技術的應用和實用化範圍,於是五十嵐教授選擇了在大學開展研究工作。作為專業研究者在對UI和交互技術的研究過程中,AI、機器學習和人機關係也逐漸成為重要的研究課題。
2017年,五十嵐教授入選了JST(日本科學技術振興機構)的 CREST(戰略性創造研究推進事業)「理解和控制數據驅動型智慧資訊系統的人機交互」項目。在CREST項目中,除了研究數據生成和訓練過程等AI技術的共通課題外,還發表了利用訓練後的結果來讓系統内部視覺化、通過客戶的適當干預來獲得期望的結果等若干應用技術。
下面將介紹其中三項重要的研究成果。第一項成果是可支持各種體型和姿勢的先進「虛擬試衣法」。儘管可以在電腦屏幕上可以虛擬試穿服裝的系統已經走進實際應用,但對於應用單純的3DCG或常用深度學習模型的系統來說,還很難即時生成逼真的試穿效果圖像。為此,五十嵐教授帶領的研究團隊從開始準備一個可以自由改變異體型和姿勢的模特機器人開始這項研究。
研究團隊為模特機器人穿上衣服,模仿不同體型的客戶的各種姿勢,拍攝了數萬張照片。通過基於這些照片數據的深度學習演算法,團隊成功實現了不同體型和姿勢下衣服的皺褶效果,以及在身體不同部位的衣服空間效果等詳細圖像生成。該系統除了應用於線上店舖的虛擬試衣外,還被用於線上會議影片中服裝變換的試驗中(圖2)。

圖2 虛擬試衣系統使用示意圖。
各種衣服的試穿結果。根據從模特機器人獲取的數據合成逼真的試衣圖像。
AI和機器學習往往被認為是數據和演算法的世界,但具體的内容生成也需要「匠人」因素和耐心來建立學習數據。五十嵐教授在回顧開發過程中的艱辛時表示:「雖然程序可以在短時間内完成,但訓練數據需要很長時間。拍攝圖片僅需要2小時左右就可以完成,但訓練卻花費了2晚。一旦失敗又要重新開始訓練,再需要2晚。這是機器學習的常見問題,就虛擬試衣法而言,從構思到完成大約花了3年時間」。
看著車的「眼睛」過馬路
降低自動駕駛的交通風險
UI和交互技術的研究不一定只是計算機端的技術。為了在人類和機器之間建立更好的互動,五十嵐教授的團隊探索了一種以人類可以理解的方式視覺化AI決策的機制。這就是第二項成果——具有「眼睛」的自動駕駛汽車。這款自動駕駛汽車通過車頭「眼睛」的角度來表示AI艙面部門甲級船員正在注意的方向,實驗中用它來測量看到汽車「眼睛」的行人過馬路的狀況。
過馬路實驗的結果表明,行人傾向於認為如果自動駕駛汽車的「眼睛」對著自己的方向,則表示車輛「正看著自己」,因此判斷過馬路是沒有問題的。而如果眼睛對著其他方向,則表示「汽車沒有在注意自己」,因此判斷過馬路是危險的。如此,通過用汽車「眼睛」所示方向來表示AI的注意方向,行人大多數情況下可以採取適當的風險規避行為,驗證了此設計有助於降低交通風險。此外,研究還發現,實驗者的風險規避行為中存在顯著的性別差異(圖3)。
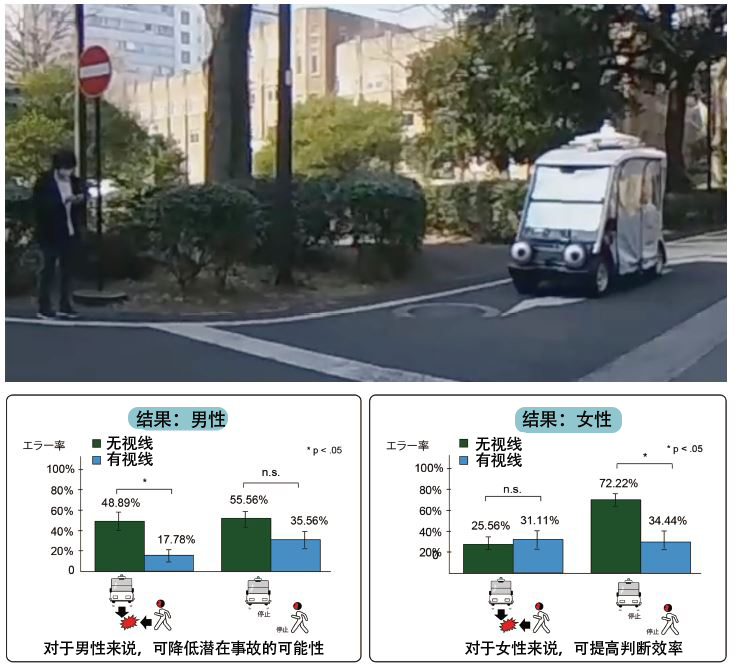
圖3 實驗調查行人對具有「眼睛」的自動駕駛汽車的反應。
如果汽車的眼睛看的方向、也即AI注意的方向剛好為行人的方向,則判斷為「安全」,否則判斷為「危險」,由此調查了行人對是否橫穿馬路的判斷。實驗中,汽車和「眼睛」均為手動操作,扮演行人角色的客戶在VR環境中進行實驗(上)。圖表顯示了有「眼睛」和沒有「眼睛」場合行人做出判斷的差異。男性和女性實驗者之間存在顯著差異(下)。
五十嵐教授總結道:「這是一項將自動駕駛汽車AI系統與汽車眼睛的運動聯繫,假設汽車眼睛的視線直接表現AI所處狀態的研究」。不久的將來,自動駕駛汽車將在公共道路上行駛,如何將自動駕駛汽車的判斷傳達給行人,從而使行人能夠正確地規避危險,將成為一個越來越重要的課題。和客戶交互的研究是必不可少。
防止AI的錯誤訓練結果
一鍵誘導正確標註位置
第三項成果是防止AI錯誤數據訓練的技術。在機器學習領域,為了防止最終訓練結果出現判斷錯誤,有時需要在訓練的過程中進行適當的人為干預。例如,要從漂浮在海上的船的圖片中學習船的形狀,學習對象必須放在船上,而不是圖片中的「波浪」或「濱海帶」等元素。此外,為了從大量人臉圖片中學習「口紅」元素,就必須關注在嘴脣上。然而,在實際的學習數據中由於「比較注重眼妝的人通常會塗口紅」,因此AI可能會錯把眼部區域作為學習對象。
這樣數據訓練的結果就是,機器學習做出錯誤判斷。這種問題被稱為「共現偏差」,防止共現偏差的發生是機器學習面臨的重大課題之一。為了消除共現偏差的影響,需要對原始數據進行適當的修改和重新收集,或者客戶直接明確特定區域,並提供應該用於訓練的部分。然而,重新收集數據集,或者讓客戶做畫素等級的區域標註等都需要大量的人力和資金成本。
為了縮減所花費的時間和精力,五十嵐教授的團隊開發了一種隻需對顯示螢幕幕上的圖片單擊滑鼠就能使AI識別特定區域的技術。以前面的船為例,如果左鍵單擊船圖像的部分,則人眼可見地船部分將會成為識別目標。反之,如果右鍵單擊船周圍水的部分,則會將水的部分從識別目標中移除。由此,可以顯著減少機器學習的訓練時間和成本,以及數據標註過程中的人力投入(圖4)。

圖4 消除AI共現偏差的一鍵標註技術示意圖。
CelebA數據集中與「口紅」相關的數據,一鍵標註前深度學習網路識別的區域示例(上)和微調後的區域示例(下)。減輕了對眼睛、臉頰等非脣部妝容的考慮。
通過人為調整來告訴AI需要關注部分的行為被稱為「注意力引導」技術,該成果的關鍵在於極大地簡化了人類引導AI應關注部分時的操作。五十嵐教授解釋道:「通過結合我們同時設計的主動學習演算法,經驗證注意力引導所需的時間減少了27%,學習準確性也有了顯著提高」。
難關的是找出新想法
邊動手邊思考最重要
除了這些應用之外,為實現多種想法,五十嵐教授還不斷開展如通過讓客戶從AI提供的各種圖片中進行選擇來生成接近客戶設想的圖像生成技術,以及僅用一個滑件即可進行複雜多樣的圖像調整技術等研究。據其稱,最困難的階段是想出誰也沒有想到的新想法。但是,一旦跨越了這一困難,就可以在活用和應用現有技術的同時直接進入應用程序的開發。
「為了提出新的想法,大量閱讀論文,姑且動手嘗試並不斷思考是極為重要的」。五十嵐教授推進科研的背景是UI和交互技術有潛力去幫助人類和計算機相互交流資訊以創造更好的結果,這與CREST的目標「建立人與資訊環境的共生交互技術的基礎」密切相關。
正如美國OpenAI公司於2022年11月發布的大語言模型生成AI「ChatGPT」引發了全世界的關注所示,可以說目前正處於AI利用歷史長河的變革期。五十嵐教授在展望研究前景時表示:「儘管我們基於已經獲得的成果來探索還能實現什麼,但基本想法從未改變。那就是實現不需要專業知識,客戶能按照自己的意圖來控制計算機系統。未來我們將繼續挑戰這個課題」。(TEXT:土肥正弘、PFOTO:伊藤彰浩)

原文:JSTnews 2023年9月號
翻譯:JST客觀日本編輯部(協助:謝浩然(北陸先端科學技術大學院大學))