生成式AI(人工智慧)的引擎——大規模語言模型(LLM)正在接連問世。各公司競相宣傳其開發的LLM性能卓越,然而與英語相比,日語環境下用於客觀評估AI性能的測試資料仍不夠完備。早稻田大學的河原大輔教授(資訊學)指出:「為了提高性能,建立日語的評估機制不可或缺。」

河原大輔教授。1999年畢業於京都大學研究生院。曾任資訊通信研究機構和京都大學副教授等職,2020年任早稻田大學基幹理工學部教授。專業為自然語言處理和智慧資訊學。
——評估AI性能的方法都有哪些?
「關於本文的AI性能評估,主流方法是2018年在美國出現的‘GLUE’測試組。該測試組涵蓋判斷句子内容是否積極或消極,以及簡單地詢問文章題目和知識問題等。我的研究室也與雅虎公司合作,製作了日語版問題與回答的測試資料。」
「然而,隨著生成式AI的發展,這些測試方式很快就過時了。如果用人類來比喻的話,這些測試面向小學生已經夠用了,但是應試者卻突然變成了大學生水平。所以新的測試方式在美國等地開始接連出現。」
「其中之一是被稱為‘MT Bench’的多方面評估方法。代表題例包括摘要、編碼、數學、邏輯問題、角色扮演等,其8個領域分別公開了精心設計的問題。許多問題的答案不僅限於一個。該方法已被廣泛用作客觀衡量英語LLM能力的指標。」
——在答案不唯一的情況下,由誰來評分?如何評分?
「若依靠人工逐個評估,既費時又費錢。目前普遍的做法是,讓被視為‘最優秀LLM’的美國OpenAI公司的‘GPT-4’進行自動評分。已有研究成果表明,這樣得到的結果與人工評估存在一定相關,並且不會偏袒與GPT-4自身情況接近的答案。」
「然而,使用AI評估AI時也存在偏差問題。會出現無關本文内容,對字數較多或率先看到的答案給予高度評價——這些也是教師評分時也容易出現的問題。還有一些問題,AI僅僅通過學習公開的測試資料就能夠提高正確率。」
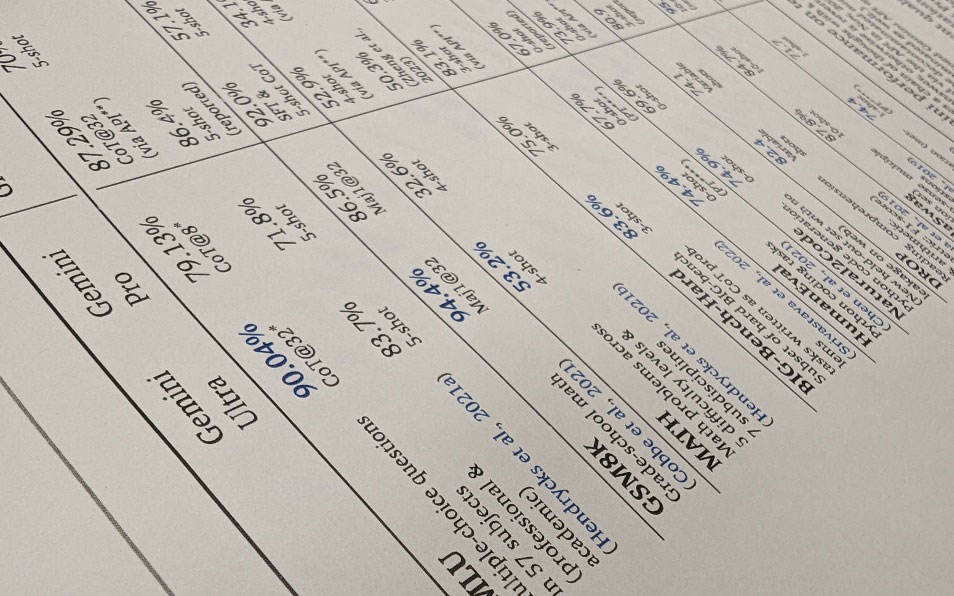
美國谷歌公司公開了高難度的多方位測試結果
——各類企業都在開發獨特的LLM並宣傳其優秀之處。
「美國谷歌和OpenAI等公司公佈了比較多樣的評估結果。然而,在日本國内企業中,有些評估案例被認為隻展示了對自家公司有利的部分。」
「事實上,日語LLM的實力還遠遠不夠。基於‘GLUE’等初級指標進行比較時,即使在日語測試中,OpenAI公司的GPT-4依然是最優秀的,而該公司的舊模型與日本企業的某些模型水平相當。如果使用更高級的測試指標,差距想必會進一步擴大。」
「與LLM的開發熱潮相比,顯影器製作日語評估數據的努力並不積極。儘管製作‘精心設計的問題與答案’的數據是一項持續而昂貴的工作,但它不僅對評估有用,對於生成式AI進行附加學習時也很重要。為了提高日語LLM的性能,數據的製作是不可或缺的。」
日文:伴正春、《日經產業新聞》、2024/2/26
中文:JST客觀日本編輯部