6月26日,日本資訊通信研究機構(NICT)宣佈,該機構的通用通信研究所成功開發出適用於21種語言的高質量且高速運行的神經元話音合成技術。利用該技術,僅用0.1秒就能在單個CPU核心上高速合成時長1秒鐘的語音。該技術比現有模型快約8倍,並實現了在未聯網的智慧型手機上,在短短0.5秒内實現從本文到語音的高速生成。
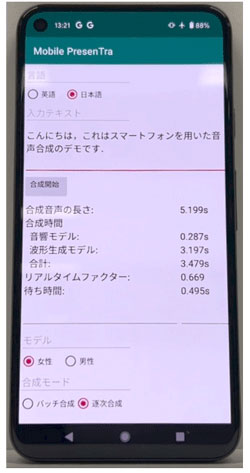
圖1:安裝在中端智慧型手機上的話音合成模型(供圖:資訊通信研究機構(NICT))
通用通信研究所已將此次開發的21種語言話音合成模型搭載在NICT運營的智慧型手機多語種語音翻譯應用程序voicetra的伺服器上,並向一般公眾開放。今後將通過商業許可等方式將其應用於多語種語音翻譯、導航等各種語音應用中。
該成果將於9月在國際語音通訊協會(International Speech Communication Association, ISCA)主辦的國際會議INTERSPEECH2024的Show&Tell上發布。
通用通信研究所將在公開為語音翻譯驗證實驗而運行的智慧型手機語音翻譯應用voicetra的同時,通過商用許可實現社會應用。。
用人的聲音將翻譯後的本文讀出來的本文話音合成技術,與話音辨識和機器翻譯一樣,對實現多語種語音翻譯技術而言非常重要。
近年來,隨著神經元網路技術的導入,本文話音合成的音質得到了顯著改善,已經發展到可以與人聲媲美的程度,然而,龐大的計算量仍然是一個較大的問題,因此在未聯網的智慧型手機上進行話音合成,此前一直被認為是完全不可能的。
另一方面,NICT在目前正在推進的中長期計劃中研究開發多語言同聲傳譯技術,由於同聲傳譯需要在不等說話人說完的情況下順次說出翻譯的語言,因此與話音辨識和機器翻譯一樣,需要本文話音合成的高速化。
本文話音合成模型包括由將輸入本文轉換為中間特徵量(將語音波形劃分為短幀並分析每幀的頻率而獲得的特徵)的「聲音模型」以及將中間特徵量轉換為語音波形的「波形生成模型」構成。
其中,在利用模擬人腦神經細胞神經元的神經元網路進行話音合成的「神經元話音合成」的聲音模型中,Transformer型編碼器+Transformer型解碼器的神經元網路被廣泛應用於機器翻譯領域、話音辨識、ChatGPT等大規模語言模型中,是此前的主流。
相比之下,通用通信研究所通過將近年來開始在圖形識別領域應用的高速、高性能ConvNeXt型編碼器+ConvNeXt型解碼器神經網路導入聲音模型,在不降低質量的情況下實現了比既往方法快3倍的速度。
此外,通用通信研究所還進一步發展了能夠合成與人聲相匹敵的原有語音波形生成模型「HiFi-GAN」,2021年將其作為會學習的神經元網路模型「MS-HiFi-GAN」信號處理方式導入進來,在不影響合成質量的情況下,成功地將合成速度提高至了原來的2倍。
2023年又進一步開發出了比「MS-HiFi-GAN」更快的「MS-FC-HiFi-GAN」模型,與既往的「HiFi-GAN」相比,在合成質量不受損的情況下,將合成速度提高至了原來的4倍。
作為這些成果的結晶,此次通用通信研究所使用「聲音模型:Transformer型編碼器+ConvNeXt型解碼器」和「波形生成模型:MS-FC-HiFi-GAN」,實現了更高速度、更高質量的神經元話音合成模型。
由此隻需一個CPU核心,就能在0.1秒内高速合成時長1秒鐘的語音。即使是在未聯網的智慧型手機(性能和價格為中等的中端產品)上,也能在0.5秒内實現從本文輸入到話音合成的高速生成。
3月起已向公眾開放
今年3月起,使用了上述最新話音合成技術的voicetra 21種語言的語音已向公眾開放。21種語言分別為:日語、英語、中文、韓語、泰語、法語、印度尼西亞語、越南語、西班牙語、緬甸語、菲律賓語、巴西葡萄牙語、高棉語、尼泊爾語、蒙古語、阿拉伯語、意大利語、烏克蘭語、德語、印地語、俄語。
原文:《科學新聞》
翻譯:JST客觀日本編輯部
【論文資訊】
期刊:Proceedings of INTERSPEECH 2024
論文:Mobile PresenTra: NICT fast neural text-to-speech system on smartphones with incremental inference of MS-FC-HiFi-GAN for low-latency synthesis